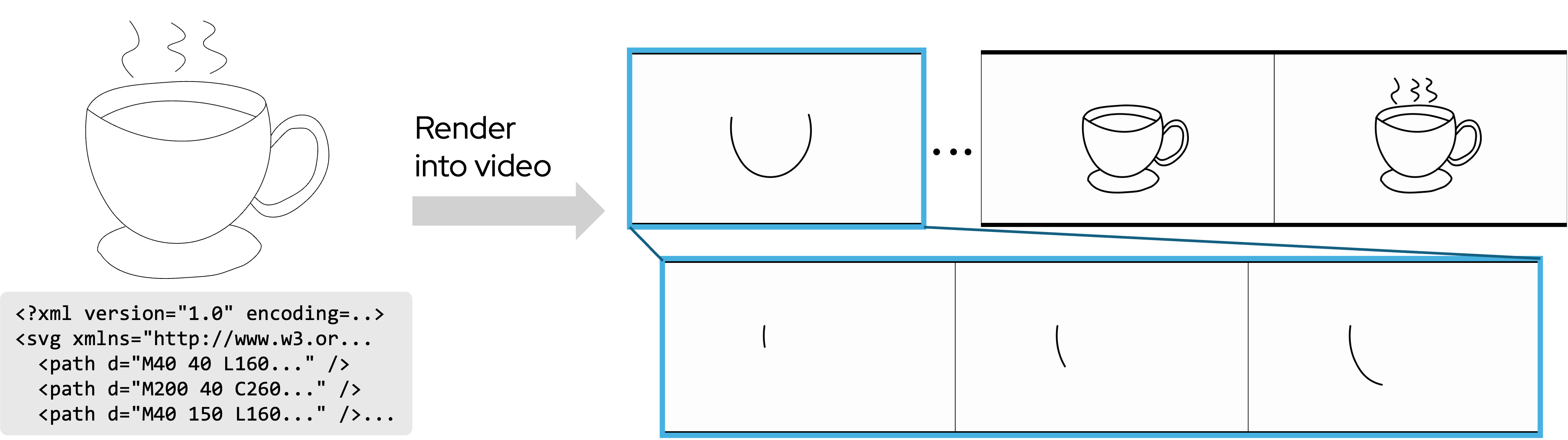
Main Gallery - Sequential Sketching
An Amsterdam canal
A Rome street with a cat
A Tokyo alley with lanterns
A traveler by a campfire
A beach at sunset
A lighthouse on a rocky shore
A medieval town square
A shepherd with sheep
A fisherman by a river
A harbor city with ships
An ancient observatory
A bakery opening at dawn
A blacksmith forge
A castle built into a cliff
A cat on a windowsill
A floating city
Floating islands
A forest with glowing mushrooms
A forest path
A glowing cave entrance
A glowing path into the unknown
A laboratory bench
A mapmaker's desk
A market street
A mechanical clocktower
A mountain lake
A Paris street at dusk
A park bench scene
A portal in a field
A rider on horseback
A rocket launch
A savanna at dusk
A scholar's tower room
A snowy village
A stone bridge over a river
A telescope on a cliff
A cake
An ice cream
A pair of pants
A sandwich
A bed
A truck
A cow
A bunch of grapes
A tent
A teapot
A camel
A pineapple
A lobster
A watermelon
A castle
An ear
A squirrel
A ceiling fan
A tooth
A hurricane
A vase
A candle
A ladder
A donut
A sleeping bag
A van
A giraffe
A hexagon
A piano
A table
A cloud
Matches
A church
A crab
A speedboat
An envelope
A penguin
A banana
A panda
A paper clip
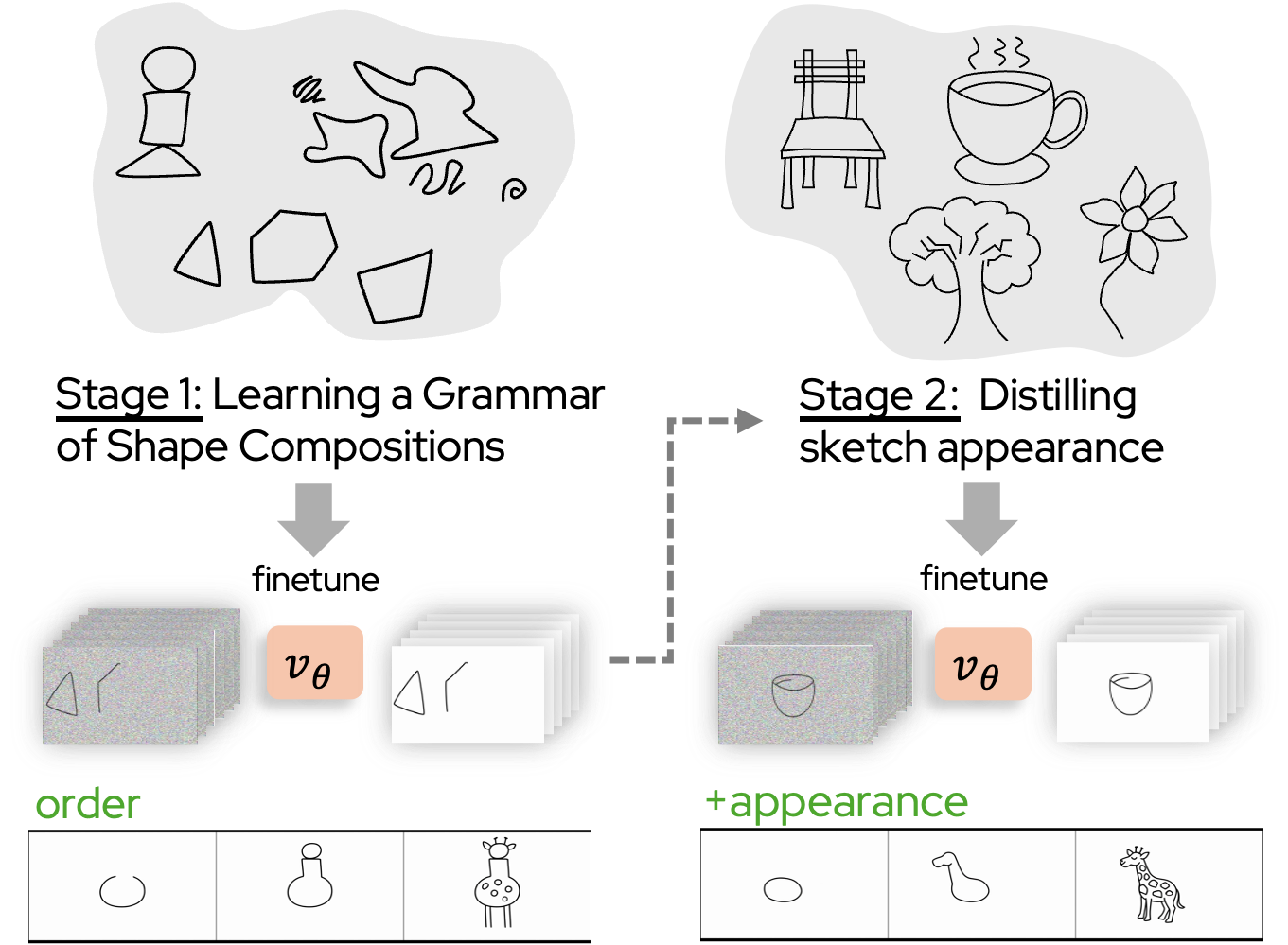
Our method generates diverse sequential sketches, ranging from single objects to complex multi-element scenes. Despite being trained on only 7 real sketches, it generalizes to complex scenes, including streets, canals, and alleys with multiple buildings, characters, and vehicles, producing clean lines, coherent perspective, and semantically meaningful stroke ordering (e.g., large structures first, fine details last).
Brush Style Gallery
A Paris street at dusk
A girl riding a unicorn in the sky
A robot looking at a mirror
A lighthouse on a rocky shore
An Amsterdam canal
A Rome street with a cat
A teapot
A tent
A hurricane
A camel
A pineapple
A lobster
A watermelon
A castle
A cake
An ice cream
Pants
A sandwich
A bed
A truck
A cake
An ice cream
Pants
A sandwich
A bed
A truck
A cake
An ice cream
Pants
A sandwich
A bed
A truck
A cake
An ice cream
Pants
A sandwich
A bed
A truck
A cake
An ice cream
Pants
A sandwich
A bed
A truck
A cake
An ice cream
Pants
A sandwich
A bed
A truck
Beyond stroke ordering, our video-based formulation offers flexibility in visual style. Conditioning on a brush exemplar in the first frame allows the model to reproduce the target brush's color and texture throughout the sketch. Notably, this generalizes to brush styles and colors not seen during training.
Autoregressive Generation
A cake
Pants
A tent
A teapot
A squirrel
A hurricane
A candle
A piano
A table
A cloud
A church
An envelope
A penguin
A paper clip
An oven
A television
A bowtie
An airplane
A cell phone
An octopus
Peas
A house
A couch
A saw
A tornado
A bridge
A basket
A flamingo
Flip flops
A fireplace
A shoe
A skull
A baseball bat
A basketball
A bee
A pig
A rake
A dishwasher
A dresser
A sink
A helicopter
A mug
A mountain
A bulldozer
A washing machine
We examine adapting our framework to autoregressive sketch generation, enabling interactive drawing scenarios that are difficult to support with diffusion-based models. The autoregressive model produces visually coherent sketches with clear stroke-by-stroke progression, although with slightly reduced visual fidelity compared to the diffusion-based approach.